Overview
Notably is for those who prefer to use a desktop app for managing notes. More importantly, Notably is optimized for those who prefer to work with a Command Line Interface (CLI) while still having the benefits of a Graphical User Interface (GUI). If you can type fast, Notably can get your notes taken down faster than traditional GUI apps.
Summary of contributions
-
Major enhancement: Added Notably’s auto correction functionality
-
What it does: Allows Notably to understand mistyped commands from user, as long as it is within a certain configured threshold. This makes it possible for the user to type faster than before, as he/she does not need to worry about wrong spelling anymore.
-
Justification: This feature improves user experience significantly, as it allows our users to type commands without worrying about wrong spelling any longer. This is really crucial, as Notably is a keyboard/CLI first note-taking application; most interactions are done via typing.
-
Highlights:
-
This enhancement calls for good abstraction. Due to the fact that this component is used the suggestions generation and command parsing aspects of Notably, I had to come up with an abstraction that minimize code duplication and at the same time is flexible for future improvements.
-
In addition, this feature requires calculating edit distance. This shows that I am able to incorporate and create suitable wrappers around complex algorithms to be used in a Software Engineering project.
-
-
Credits: The implementation of the edit distance algorithm is inspired by https://web.stanford.edu/class/cs124/lec/med.pdf.
-
-
Major enhancement: Wrote Notably’s Markdown to HTML compiler
-
What it does: Allows Notably to compile Markdown into HTML.
-
Justification: This feature improves user experience significantly, as it allows our users to format their notes using the Markdown syntax. This is really crucial, as Notably is a keyboard/CLI first note-taking application; GUI-based text formatting solution would not work well.
-
Highlights: This enhancement requires me to learn basic compilation techniques, such as tokenizing, parsing, and target code generation. Although Markdown is not a complex syntax, building a Markdown to HTML compiler following the techniques prove to be quite challenging.
-
Credits: The implementation of the compiler is inspired by https://github.github.com/gfm/#appendix-a-parsing-strategy.
-
-
Code contributed: [Functional code] [Test code]
-
Other contributions:
-
Software architecture: Designed Notably’s overall architecture. In addition, I held a meeting with my teammates to get everyone on the same page about Notably’s overall architecture.
-
Community:
-
Tools:
-
Integrated Codecov (code coverage analysis tool) into Notably’s development workflow (#386)
-
Integrated Netlify into Notably’s development workflow
-
-
Contributions to the User Guide
Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. |
Auto correction
Notably will try its best to correct your mistypes automatically, as long as your mistyped inputs are not too far away from the understood commands. This provides you with a more fluid typing experience!
Notably’s auto correction feature works on two aspects of your typing:
-
It auto corrects command names, where command names refers to
open,search,delete,edit, and others. For example, Notably will correct the mistyped command nameopnetoopen. -
It auto corrects the
Pathsof notes. For example, depending on the notes that exist in your database, Notably might correct/Notabyto/Notably.
See the example below for more information.
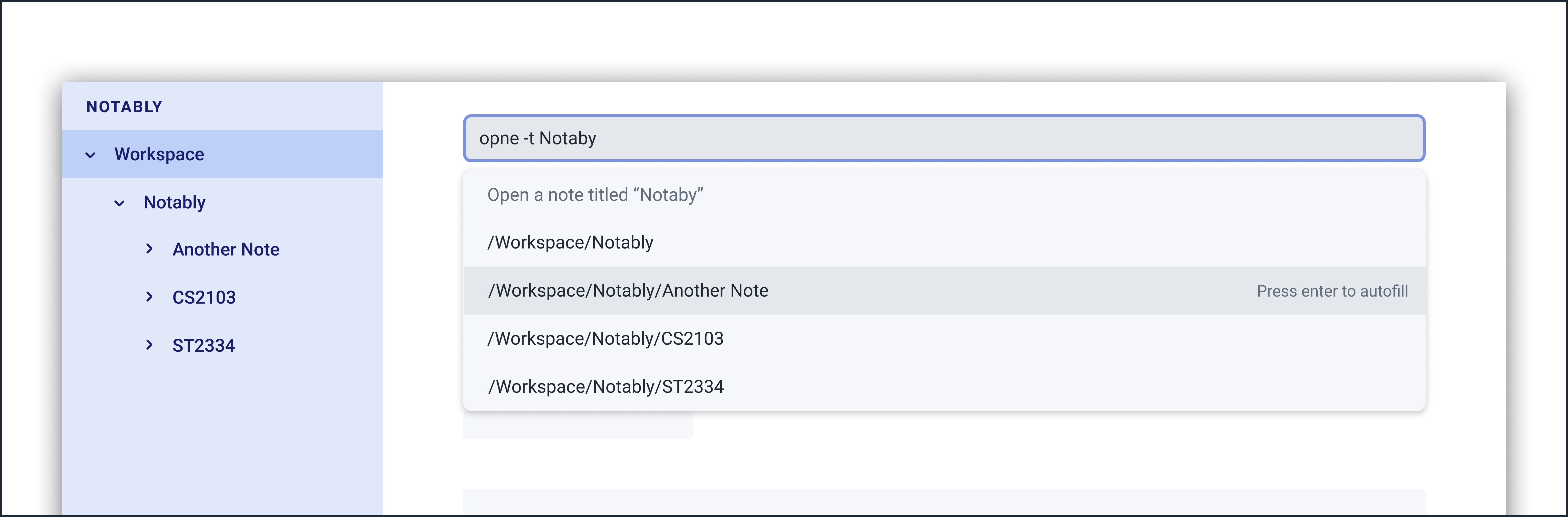
Example: Auto correcting user input
Even though the user types in the command name opne, Notably is still able to recognise this as an open command.In addition, the inputted RelativePath Notaby is understood by Notably, even though there’s no note in the database with the title Notaby. Instead, there exists a note in the database with the RelativePath Notably.After corrections are done, a list of suggestions will be generated as if the user has inputted open -t Notably!
|
Markdown (GitHub Flavored Markdown)
| We use the term Markdown and GitHub Flavored Markdown interchangably in this document. |
Notably supports basic GitHub Flavored Markdown (GFM) as the BODY content of a note.
By supporting Markdown, we hope to enhance your typing experience even further. You can simply type your note in Markdown, and it’ll take care of displaying the content of your note in a nice layout for you.
Currently supported syntax of GitHub Flavored Markdown in Notably consists of:
# Level 1 header ## Level 2 header ### Level 3 header #### Level 4 header ##### Level 5 header ###### Level 6 header
-
Lists and List items
Currently, only unordered lists are supported. In addition, only the hyphen -symbol is supported to be used as the list bullets.
- List item
- Another list item
- A nested list item
- A deeper nested list item
- Last list item
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Proin dictum accumsan nunc sed feugiat.
Example: Writing your note in Markdown
For example, you might write your note as follows:
# Hello Notably Notably is for those who prefer to use a desktop app for managing notes. More importantly, Notably is optimized for those who prefer to work with a Command Line Interface (CLI) while still having the benefits of a Graphical User Interface (GUI). ## Getting started - Ensure you have Java `11` or above installed in your Computer. - Download the latest https://github.com/AY1920S2-CS2103T-W17-2/main/releases[notably.jar] - Double-click the file to start the app. The Application should start in a few seconds.
(Coming in v2.0) More complete support of Markdown syntax
In our v2.0 release, we’ll be supporting the following additional Markdown syntax:
*This text will get italicised* **This text will get bold**
~~This text will get a strikethrough treatment~~
Contributions to the Developer Guide
Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
Architecture
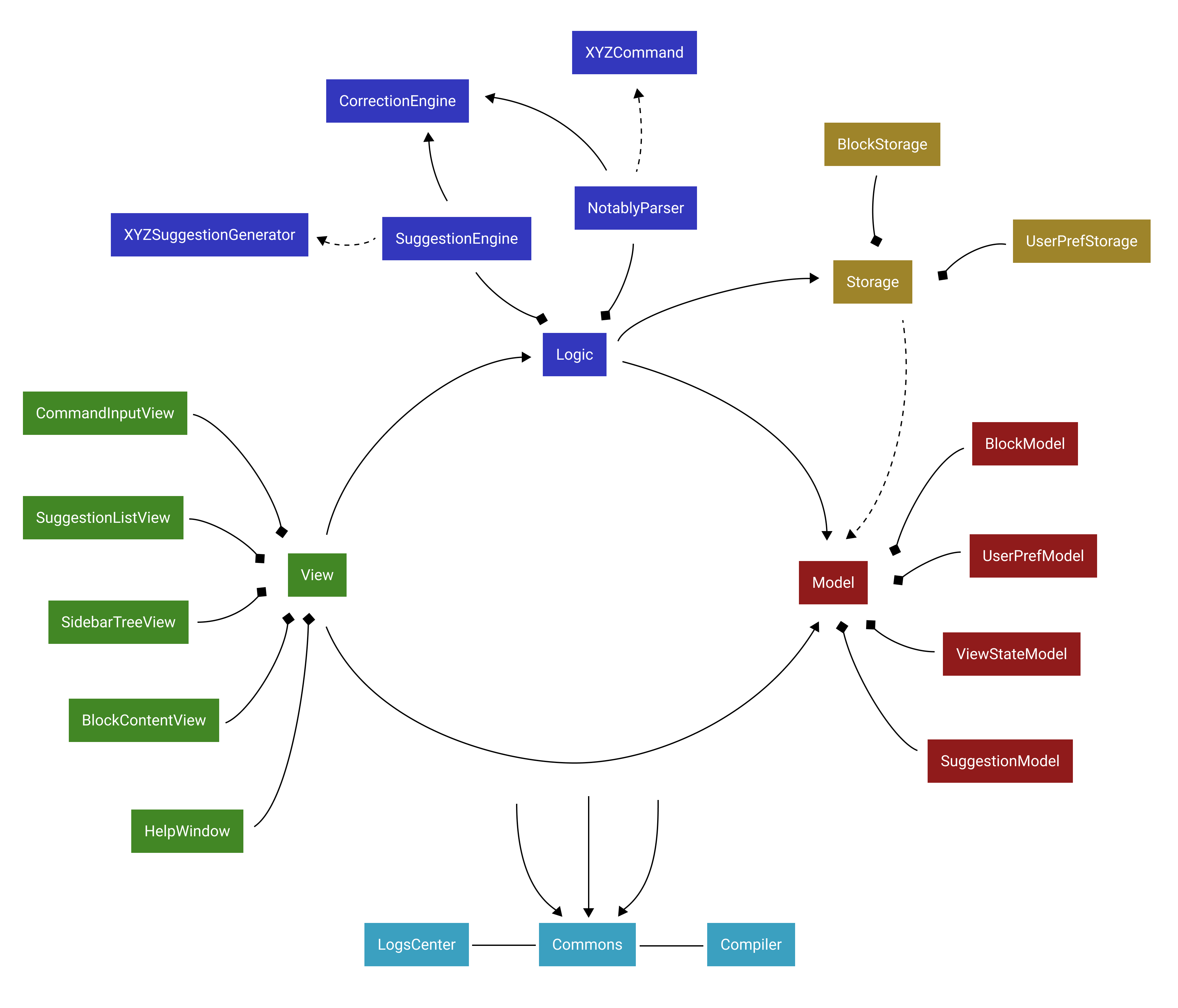
Design pattern and data flow
The App is built following the Model-View-Controller design pattern.
In addition, the App’s data flow is unidirectional. That is, all user interactions in View will trigger an appropriate handler in Logic, which in turn updates Model and Storage.
Any data/state changes in Model will then propagate back to View automatically through JavaFX’s Property and Binding. In other words, the Observer design pattern is employed; Model is the observable while View is the observer.
Architecture-level components
Overall, the App consists of five main components:
-
Defines its API in an
interfacewith the same name as the itself, e.g.Logic.java -
Exposes its functionality using a
{Component Name}Managerclass, e.g.LogicManager.java
The following classes from Commons plays an important role at the architecture level:
How the architecture components interact with each other
The Sequence Diagram below shows how the components interact with each other for the scenario where the user issues the command new -t Notably.
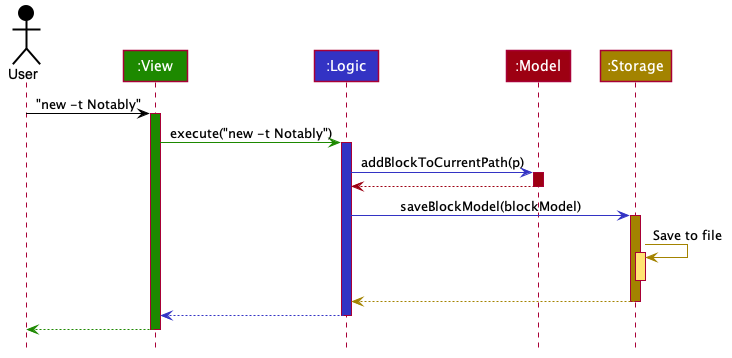
new -t Notably commandLogic
API :
Logic.java
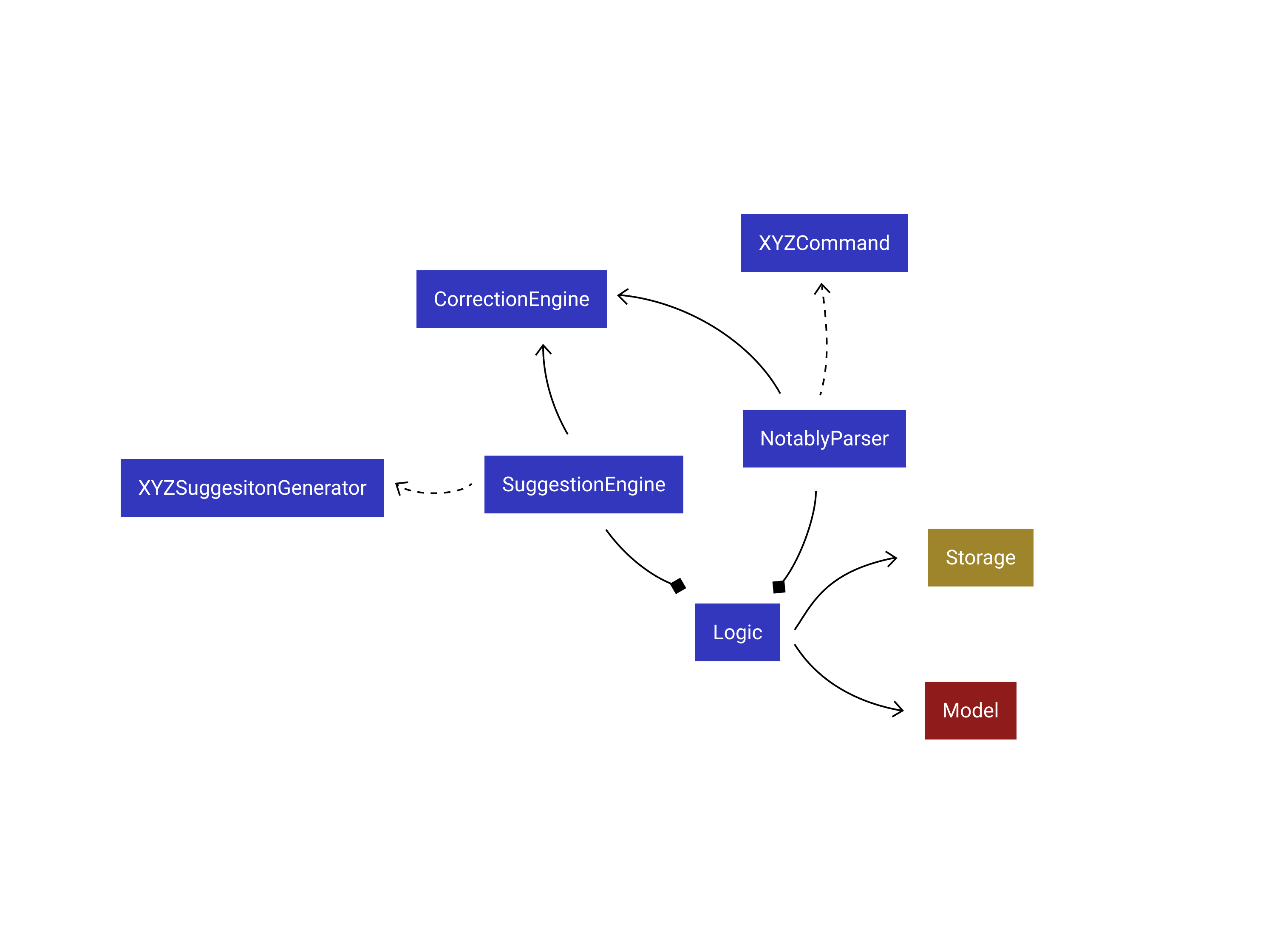
Logic consists of 3 subcomponents:
-
NotablyParser: Main parser of the App, deals with user command execution. -
SuggestionEngine: Deals with suggestions generation. -
CorrectionEngine: Deals with auto-correction.
CorrectionEngine
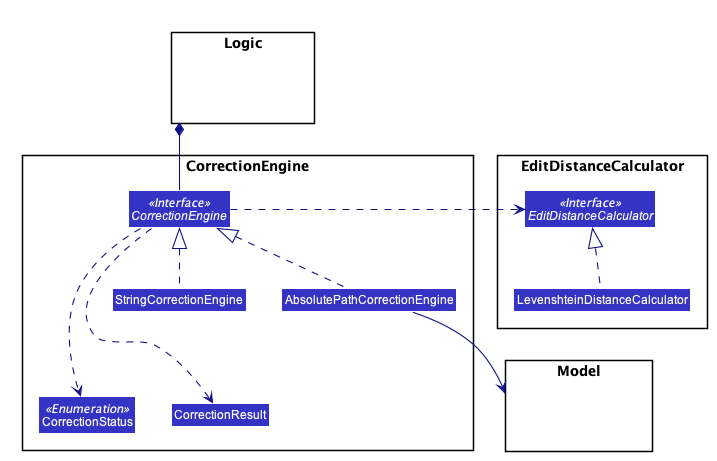
The CorrectionEngine component revolves around two API s, namely:
-
The
CorrectionEngineinterface, implemented byStringCorrectionEngineandAbsolutePathCorrectionEngine. Concrete implementations ofCorrectionEngineare employed to correct an uncorrected user input. -
The
EditDistanceCalculatorinterface, implemented byLevenshteinDistanceCalculator. Concrete implementations ofEditDistanceCalculatorare employed to calculate the edit distance between two strings.
Given below is the Sequence Diagram for interactions within the StringCorrectionEngine (one concrete implementation of CorrectionEngine) component for the correct("uncorrected") API call.

correct("uncorrected") callCorrection Engine
Rationale
CorrectionEngine is needed to enable auto-correction of user inputs, to deliver as good typing experience as possible.
Current implementation
The CorrectionEngine component revolves around two API s, namely:
-
The
CorrectionEngineinterface, implemented byStringCorrectionEngineandAbsolutePathCorrectionEngine. Concrete implementations ofCorrectionEngineare employed to correct an uncorrected user input. -
The
EditDistanceCalculatorinterface, implemented byLevenshteinDistanceCalculator. Concrete implementations ofEditDistanceCalculatorare employed to calculate the edit distance between two strings.
Two concrete implementations of the CorrectionEngine interface are, namely:
-
The
StringCorrectionEngineclass, which deals with the correction of plain strings. -
The
AbsolutePathCorrectionEngineclass, which deals with the correction of absolute paths. The absolute paths here refer to the address of the notes (or blocks, as we call it) that exist in the App.
Design considerations
-
CorrectionEngineis built as a standalone module that can be used by bothSuggestionEngineandParser. This decision is made so that code duplication in relation to auto-correction is minimal. -
Both
CorrectionEngineandEditDistanceCalculatorare implemented as interfaces, in an attempt to make the design of theCorrectionEnginecomponent resilient to change. This design enables us to leverage on the strategy pattern to make ourCorrectionEnginecomponent more future-proof.
Compiler
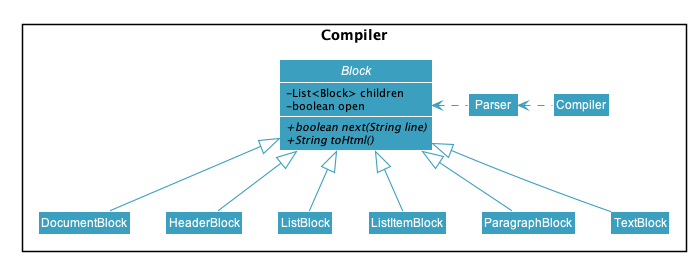
The Compiler component’s primary usage is to compile Markdown to HTML.
Our Compiler component’s design is based off the parsing strategy explained in GitHub’s GFM Specification
Mainly, the Compiler component consists of the following classes:
-
Compiler, which deals with the end-to-end job of compiling unprocessed Markdown to HTML. -
Parser, which deals with creating an Abstract Sytax Tree representation of an unprocessed Markdown. -
Block, which is an abstract class representing a node in a Markdown Abstract Syntax Tree. All concrete implementations of nodes in a Markdown Abstract Syntax Tree inherit from this class.
The concrete implementations of the Block class consist of:
-
DocumentBlock, which represents the root of the Markdown Abstract Syntax Tree. -
HeaderBlock, which represents a Markdown ATX heading component. -
ListBlock, which represents a Markdown unordered list. -
ListItemBlock, which represents a Markdown list item. -
ParagraphBlock, which represents a Markdown paragraph. -
TextBlock, which represents plain text in Markdown.
Two of Block's abstract methods are particularly important:
-
Block#next: This method should be implemented by each ofBlock's implementation in such a way that accepts a singleStringline and evolve the current Markdown Abstract Syntax Tree further. That way, each ofBlock's implementation only needs to care about processing the portion of theStringline that is relevant to them, before delegating the rest to its childrenBlocks. -
Block#toHtml: This method should be implemented by each ofBlock's implementation in such a way that it returns the HTML representation of the currentBlock. That way, each ofBlock's implementation only needs to care about generating its own HTML; the rest can be delegated to its childrenBlocks.
In short, our Compiler class will first call the Parser#parse method to generate a Markdown Abstract Syntax Tree.
After that, the Compiler class will transform the returned Markdown Abstract Syntax Tree into HTML by calling the root DocumentBlock's toHtml method (which will in turn invoke each of its children’s toHtml method).
Given below is the Sequence Diagram for interactions within the Compiler component for the compile(markdown) API call.
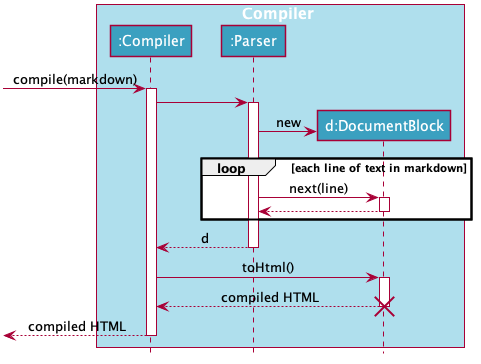
compile(markdown) callCompiler
Rationale
Compiler is needed to enable compilation of Markdown to HTML. By having an Markdown to HTML compiler, we can allow user to format their notes in Markdown, which enhances their note-editing experience tremendously.
Current implementation
The implementation of Compiler is highly inspired by the parsing strategy explained in GitHub’s GFM Specification. Please read more from the specification for a more comprehensive explanation.
Design considerations
Generally speaking, compilers usually consist of several main components, namely a tokenizer, a parser, and a generator. However, this is not the case in our design of the Compiler component:
-
Leveraging on the fact that Markdown’s syntax is not overly complicated, we decided not to fully adhere to the usual compiler design. Instead, we merged the tokenizer and parser section into our
Parserclass. ThisParserclass thus deals converting raw Markdown string into a Markdown Abstract Syntax Tree. -
In addition, we opted to not build a standalone generator component. Instead, we make it such that each node in our Markdown Abstract Syntax Tree supports a
toHtmlmethod, which returns the HTML representation of the tree starting from itself as a node. This way, we can leverage on OOP’s polymorphism to generate the HTML string out of our Markdown Abstract Syntax Tree a lot easier.